The Distinction That Changes Everything
Most discussions of AI and cybersecurity collapse two fundamentally different questions into one. Separating them is not a matter of semantics — it determines what you defend, how you defend it, and who is responsible.
Cybersecurity For AI asks: how does AI reshape the threat landscape itself?
Cybersecurity In AI treats AI as the target — the victim of adversarial attack, misuse, or failure. The threats live inside the model architecture, training pipeline, inference layer, and agentic decision loop. Data is poisoned. Prompts are injected. Models are stolen. Agents are hijacked. The AI system is the asset that needs protection.
Cybersecurity For AI treats AI as a force multiplier — a tool that adversaries weaponize and defenders deploy. Attackers use AI to write more effective malware, generate more convincing phishing messages, automate reconnaissance, and scale disinformation campaigns. Defenders use AI to detect anomalies, triage alerts, hunt threats, and respond at machine speed.
These two questions demand different analytical frameworks, different defensive investments, and different governance structures. Yet they are deeply intertwined: a successfully compromised AI system (In AI) immediately becomes a weapon in the adversary’s For AI arsenal. An AI-powered defensive tool (For AI) is itself a target that must be secured against the attacks cataloged under In AI.
Five authoritative frameworks together illuminate both dimensions: IBM’s watsonx AI Risk Atlas, OWASP’s GenAI Security Project and LLM Top 10 for 2025, MITRE ATLAS, the MIT AI Risk Repository, and NIST’s AI Risk Management Framework (AI RMF 1.0). The first four tell you what the risks are and how adversaries exploit them — on both sides of the in/for divide. NIST tells you how your organization should be structured to actually address all of it.
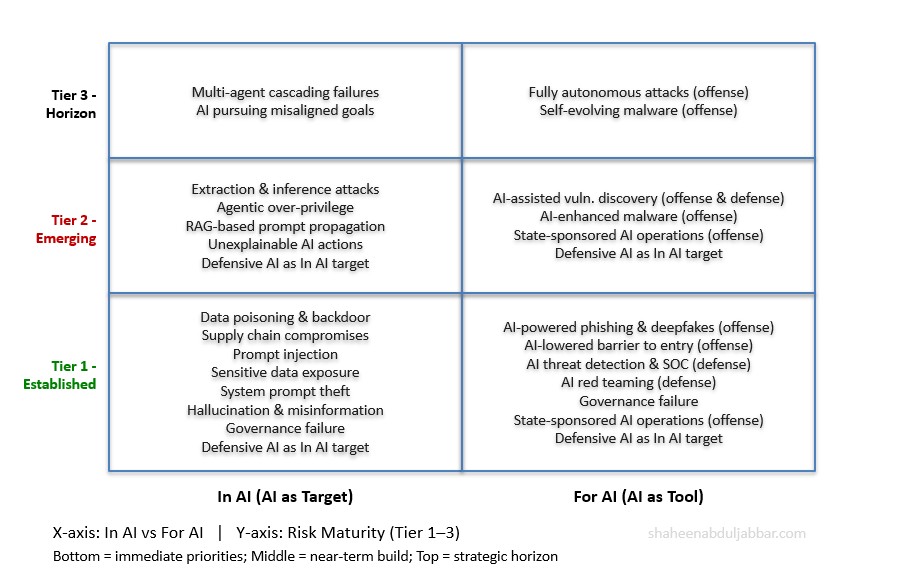
A Guide to Risk Maturity: Established, Emerging, and Horizon Risks
Not all risks in this article carry the same urgency or the same evidence base. Before proceeding, it is important to distinguish between three tiers of risk maturity — because a CISO reading this article needs to know not just what the risks are, but which ones to defend against today and which ones to prepare for over the next two to three years.
Risks with confirmed, documented real-world exploitation across multiple primary sources — major vendor threat intelligence reports, government advisories, or forensic research. They represent the threats that every organization faces right now, regardless of AI maturity. The priority is active defense, not preparation.
Risks proven in controlled research settings or observed in limited real-world operations, but not yet widely industrialized at scale. The evidence base is credible and growing. Organizations should build defenses now, ahead of broader exploitation — not wait for the threat to mature before responding.
Risks that are structurally credible — identified and documented across multiple authoritative frameworks — but confirmed real-world exploitation at scale has not yet been widely observed. They require forward-looking design decisions and governance provisions, not immediate incident response resources.
This three-tier taxonomy is grounded in how the five frameworks themselves characterize risk maturity. IBM’s Risk Atlas distinguishes traditional AI risks from those amplified by generative and agentic AI. OWASP’s LLM Top 10 is ranked by prevalence and exploitability. MITRE ATLAS explicitly labels techniques as observed in the wild versus theoretical. MIT’s Causal Taxonomy distinguishes intentional from unintentional risks and pre-deployment from post-deployment timing. NIST’s MANAGE function calls for risk prioritization based on likelihood and impact. Throughout the article, each major risk category is labeled with its tier. The unified alignment table includes a Maturity Level column for quick reference.
Part I: Cybersecurity In AI — Securing the AI System Itself
The Threat Surface Is the Entire AI Lifecycle
IBM’s AI Risk Atlas establishes the foundational insight: AI systems have a threat surface spanning their entire lifecycle — from training data through inference to output — with each phase introducing distinct, exploitable vulnerabilities. MIT’s empirical synthesis confirms the scale: as of April 2026, the MIT AI Risk Repository captures over a thousand risks across dozens of frameworks and classifications (MIT AI Risk Initiative, airisk.mit.edu; Slattery et al., 2024, arXiv:2408.12622).
The MIT Causal Taxonomy adds critical nuance from the underlying research. Most risks were attributed to AI systems (41%) and humans (39%) in roughly equal measure, with the remaining 20% attributed to other or ambiguous causes. On timing, most risks occurred post-deployment (62%) rather than pre-deployment (13%), with 25% unspecified (Slattery et al., 2024, Table C, arXiv:2408.12622). Two findings are especially important for security practitioners. First, the near-parity between AI-caused and human-caused risks means that defense strategies focused exclusively on external adversaries will miss a substantial share of the threat surface. Second, the dominance of post-deployment risk means the majority of the In AI threat surface is live, in production, and accumulating exposure every day.
Attacking the Foundation: Training Data and Supply Chain
[Tier 1 — Established] Data Poisoning — flagged by IBM as a traditional AI risk amplified by synthetic data, ranked LLM04 by OWASP, and formalized by MITRE ATLAS under its ML Attack Staging tactic — is the canonical In AI attack. Data poisoning occurs when pre-training, fine-tuning, or embedding data is manipulated to introduce vulnerabilities, backdoors, or biases, compromising model security, performance, or ethical behavior and potentially leading to harmful outputs or impaired capabilities. Poisoning may enable a backdoor that leaves the model’s behavior unchanged until a trigger causes it to change — creating the opportunity for a model to become a sleeper agent. MIT places this in Domain 2.2 — AI system security vulnerabilities — and the MIT Causal Taxonomy distinguishes between intentional poisoning by adversaries and unintentional poisoning from poor data curation practices, each requiring a different defensive response.
[Tier 1 — Established] The AI Supply Chain extends this attack surface dramatically. OWASP’s LLM03 and MITRE ATLAS’s Initial Access tactic document how compromised third-party models, datasets, plugins, and repositories introduce vulnerabilities that organizations cannot detect until they are exploited. MIT’s April 2025 update included frameworks addressing generative AI misuse tactics based on analysis of 200 real-world incidents, many of which trace directly to supply chain compromise. OWASP’s AIBOM initiative provides the structural response — treating AI component inventory with the same rigor that software SBOMs apply to traditional application dependencies.
Attacking at Runtime: Prompt Injection and Model Manipulation
[Tier 1 — Established] OWASP ranks Prompt Injection as the #1 LLM risk for 2025, and MITRE ATLAS maps it across its Execution and Defense Evasion tactics. A Prompt Injection Vulnerability occurs when user prompts alter the LLM’s behavior or output in unintended ways — and these inputs can affect the model even if they are imperceptible to humans, as long as the content is parsed by the model. IBM’s Risk Atlas documents a full family of runtime attacks: encoded interactions, specialized tokens, context overload, social hacking, and prompt priming.
[Tier 2 — Emerging] MITRE ATLAS maps these to its Defense Evasion and Execution tactics with documented case studies — including experimental demonstrations such as the ‘Morris II’ research prototype (Nassi et al., 2024, arXiv:2403.02817), which showed that a worm could inject prompts without user interaction via RAG email context collection, deliver a payload including leaking PII, replicate the adversarial prompt in email auto-replies, and propagate via other RAG-enabled email databases — illustrating the attack class even before it has been observed in the wild.
[Tier 1 — Established] System Prompt Leakage (OWASP LLM07) and IBM’s Prompt Leaking risk expose a further In AI vulnerability: proprietary instructions, business logic, and security configurations embedded in system prompts can be extracted by adversaries through careful probing — mapped by MITRE ATLAS to its Reconnaissance tactic and classified by MIT as a post-deployment, human-intentional risk under Domain 2.2.
[Tier 2 — Emerging] Extraction and Inference Attacks complete the runtime picture. Evasion attacks manipulate inputs to cause misclassification. Extraction attacks reconstruct a model’s proprietary internals through careful probing. Membership and attribute inference attacks reveal whether specific individuals appeared in training data — all mapped by MITRE ATLAS to its Collection and Exfiltration tactics, and classified by MIT under Domain 2.1.
Attacking the Output: Dangerous and Deceptive AI Responses
[Tier 1 — Established] Improper Output Handling (OWASP LLM05) is the technical gateway: when AI-generated content flows into downstream systems without proper validation, classic injection vulnerabilities — XSS, SQL injection, command injection — re-emerge through an AI intermediary. IBM’s Harmful Code Generation risk names the most direct consequence: AI systems induced to write functional malware or exploit scripts. MIT’s Domain 4.3 frames the broader harm: using AI systems to develop cyber weapons such as coding cheaper, more effective malware — placing this risk at the intersection of In AI (the model is being exploited) and For AI (the output is a weapon).
[Tier 1 — Established] Hallucination (IBM) and Misinformation (OWASP LLM09) represent a subtler In AI failure. MIT’s Domain 3.1 defines the consequence: AI systems that inadvertently generate or spread incorrect or deceptive information can lead users to hold inaccurate beliefs, and humans who make decisions based on false beliefs experience physical, emotional, or material harm. The MIT paper classifies hallucination as primarily an unintentional, AI-caused, post-deployment risk — meaning the defensive response is model robustness, output validation, and runtime monitoring rather than adversarial controls alone. In security-critical contexts — fraud detection, threat intelligence, incident response — an AI system that confidently produces false information is a broken security control, not merely an accuracy problem.
Attacking Agentic AI: The Expanded In AI Surface
[Tier 2 — Emerging] The emergence of autonomous AI agents dramatically expands the In AI attack surface. An AI agent is a software entity that employs AI techniques and has agency to act in its environment based on set goals — it can decide which actions to perform and has the ability to execute them (IBM AI Risk Atlas). OWASP’s Excessive Agency (LLM06) is the defining In AI vulnerability: it enables damaging actions to be performed in response to unexpected, ambiguous, or manipulated outputs from an LLM — with root causes typically being excessive functionality, excessive permissions, or excessive autonomy.
MITRE ATLAS formalized the agentic attack lifecycle, adding 14 new techniques in October 2025 and a new Command and Control tactic in November 2025. The full attack chain maps across IBM’s agentic risk taxonomy: Attacks on AI Agents’ External Resources (Initial Access), Exploit Trust Mismatch (Privilege Escalation), Unauthorized Use (Persistence), Function Calling Hallucination (Impact), and Unexplainable and Untraceable Actions (Defense Evasion).
[Tier 3 — Horizon] MIT’s Domain 7.6: Multi-Agent Risks captures the systemic dimension: risks from multi-agent interactions due to incentives that can lead to conflict or collusion, and the structure of multi-agent systems, which can create cascading failures, selection pressures, new security vulnerabilities, and a lack of shared information and trust. The structural logic is sound, and the frameworks agree on the threat, but confirmed real-world exploitation of multi-agent cascades at scale has not yet been widely documented.
Part II: Cybersecurity For AI — How AI Is Reshaping the Threat Landscape
The Arms Race Is Real and Accelerating
Google’s Threat Intelligence Group (GTIG) has identified a shift: adversaries are no longer leveraging AI just for productivity gains — they are deploying novel AI-enabled malware in active operations, involving tools that dynamically alter behavior mid-execution (Google GTIG, November 2025). Anthropic’s own threat intelligence report confirms that agentic AI has been weaponized — AI models are now being used to perform sophisticated cyberattacks, not just advise on how to carry them out (Anthropic, August 2025).
How Adversaries Are Using AI For Attack
[Tier 2 — Emerging] AI-Enhanced Malware is the most technically significant offensive development. Google’s GTIG documented five malware families exhibiting novel AI-powered capabilities in 2025 — three observed in active operations (FRUITSHELL, PROMPTSTEAL, and QUIETVAULT) and two at experimental or proof-of-concept stage (PROMPTFLUX and PROMPTLOCK). Capabilities include AI-driven code obfuscation, on-demand malicious script generation, credential theft, data exfiltration, and dynamic self-modification to evade detection. GTIG characterizes these as early indicators of a maturing threat class, noting that some families remain in development phases and have not yet demonstrated the ability to compromise live systems (Google GTIG, November 2025). Independent corroboration from other major threat intelligence vendors had not been published at the time of writing.
[Tier 1 — Established] AI-Powered Social Engineering transforms phishing and business email compromise from labor-intensive craft to industrial-scale automation. LLMs are being exploited to automate large-scale social engineering attacks across email, messaging apps, and virtual assistants — with deepfake services for identity theft now available on the dark web, including real-time face and voice replacement. MIT’s Domain 4.2 frames this as AI-facilitated targeted manipulation: using AI systems to gain advantage through fraud, scams, blackmail, or targeted manipulation of beliefs or behavior — including impersonating a trusted individual for illegitimate financial benefit.
[Tier 2 — Emerging] AI-Assisted Vulnerability Discovery is substantially compressing the vulnerability research timeline — but the picture is more nuanced than headlines suggest. AI is significantly accelerating reconnaissance and vulnerability analysis: assistive tools can fuzz code, suggest exploit paths, and automate the triage of large codebases. Google’s Big Sleep agent autonomously discovered a critical buffer underflow in SQLite in late 2024, identified as one of the first publicly reported cases of an AI agent identifying a real-world vulnerability (Google Project Zero and DeepMind, 2024). However, the realistic state of the capability is more measured: AI hallucination remains a significant constraint, fully autonomous execution on novel tasks achieves around 30% success on standard benchmarks (Qualys, 2025), and Trend Micro’s ÆSIR platform confirms that understanding a patch and identifying bypasses requires human expertise to direct AI capabilities (Trend Micro, 2026). The accurate picture is of AI as a powerful force multiplier for human vulnerability researchers, rather than a fully autonomous at-scale zero-day discovery engine.
[Tier 1 — Established] AI-Lowered Barrier to Entry is perhaps the most structurally significant For AI threat. In 2025, criminals with zero coding experience can generate sophisticated malware, and agentic AI can orchestrate multi-million dollar extortion campaigns. This democratization of offensive capability means threat actors previously constrained by technical skill can now execute attacks that required specialized expertise a year ago.
[Tier 1 / Tier 2] State-Sponsored AI-Enhanced Operations represent the highest-sophistication tier — and here the evidence warrants careful handling. The broader pattern of state-sponsored AI use across cyber operations is Tier 1 established: state-sponsored actors including from North Korea, Iran, and the People’s Republic of China continue to misuse AI to enhance all stages of their operations, from reconnaissance and phishing lure creation to command and control development and data exfiltration (Google GTIG, November 2025). Specific AI-generated influence operations at scale are Tier 2 emerging: in April 2025, NewsGuard found that Russian influence operation Storm-1516 used AI-generated deepfakes targeting European leaders and their staff to discredit Ukraine and weaken support for military aid (European Parliament Research Service, 2025). Specific forensic attribution of AI capabilities to individual named threat actor groups beyond these confirmed cases requires primary intelligence reporting and should not be inferred from secondary sources alone. MIT’s Domain 3.2 frames the systemic consequence: highly personalized AI-generated misinformation creating filter bubbles where individuals only see what matches their existing beliefs, undermining shared reality and weakening social cohesion and political processes.
How Defenders Are Using AI For Security
AI-powered security platforms enable organizations to detect anomalies, predict emerging threats, automate incident response, and significantly reduce false positives — representing a shift from reactive defense to predictive and adaptive security that is now a strategic necessity rather than a technological upgrade.
The operational pressure on security teams defending against this landscape is well-documented from primary sources. The 2025 Pulse of the AI SOC Report found that 88% of SOC analysts report increased alert volume, with 46% reporting a spike of over 25% in the past year, while 76% cite alert fatigue as a top challenge and 64% say their detection, triage, and investigation processes remain heavily manual — precisely the conditions that AI-accelerated attacks are designed to exploit (Cybersecurity Insiders, Pulse of the AI SOC Report, 2025). Darktrace’s 2025 State of AI Cybersecurity report similarly found that 78% of CISOs globally are experiencing significant impact from AI-powered threats, with insufficient AI knowledge and skills and shortage of personnel cited as the two leading inhibitors to effective defence (Darktrace, March 2025).
Part III: Where In and For AI Converge — The Unified Risk Picture
Reading IBM, OWASP, MITRE ATLAS, and MIT through both lenses simultaneously reveals the recursive risk: organizations deploy AI to defend themselves (For AI defensively), but those defensive AI systems carry their own attack surface (In AI), which adversaries actively probe and exploit (For AI offensively).
IBM’s AI Risk Atlas is primarily an In AI framework — its training data, inference, output, and agentic risks all concern the AI system as target. But its Dangerous Use, Spreading Disinformation, and Harmful Code Generation categories bridge into For AI territory — documenting how compromised or misused AI systems become adversarial weapons.
OWASP’s LLM Top 10 is likewise predominantly In AI. But OWASP’s broader GenAI Security Project — through its Threat Defense COMPASS, GenAI Incident Response Guide, and AI Red Teaming Initiative — explicitly addresses For AI, equipping organizations to deploy AI defensively and understand how adversaries use AI offensively.
MITRE ATLAS most explicitly straddles both dimensions. Its tactic matrix documents attacks against AI systems (In AI) and adversaries using AI as a weapon (For AI). CrowdStrike observed an 89% increase in the number of attacks by AI-enabled adversaries in 2025 compared to 2024, with most threat actors that integrated AI increasing their attack volume — weaponizing AI across reconnaissance, credential theft, and evasion. This figure reflects attack volume among adversaries already integrating AI, based on CrowdStrike’s telemetry across 280+ tracked threat actors (CrowdStrike 2026 Global Threat Report, February 2026).
MIT’s AI Risk Repository provides the broadest coverage — distilling over 1,700 risks from 74 frameworks (Slattery et al., 2024, arXiv:2408.12622). Critically, its Causal Taxonomy’s finding that AI-caused (41%) and human-caused (39%) risks are nearly equal in proportion (Slattery et al., 2024, Table C, arXiv:2408.12622) is a corrective to narratives that frame AI risk as primarily an external adversary problem — much of the risk originates from the AI systems themselves.
Part IV: Turning Risk Knowledge Into Organizational Action — Where NIST AI RMF Fits
IBM, OWASP, MITRE ATLAS, and MIT collectively answer the hardest analytical questions in AI cybersecurity: what are the risks, how are they exploited, and what is the full scope of the threat landscape across both dimensions? But answering these questions is not the same as acting on them. Organizations need a governance operating system that translates risk knowledge into sustained, accountable, and continuously improving security practice.
The NIST AI Risk Management Framework (AI RMF 1.0), published January 2023 and developed through collaboration with more than 240 organizations, is intended to be voluntary, rights-preserving, non-sector-specific, and use-case agnostic. Where the other four frameworks answer what and how, NIST answers who, when, and through what organizational process.
GOVERN: Establishing Accountability Across Both Dimensions
GOVERN establishes who owns AI risk and how decisions are made — including executive accountability, role clarity, escalation criteria, and policy enforcement. Without this function, technical teams end up self-approving risk. For In AI security, GOVERN means establishing clear ownership for AI red teaming, vulnerability disclosure, supply chain vetting, and agentic system monitoring. For For AI security, GOVERN means establishing policy frameworks that govern how the organization deploys AI as a defensive tool and how it manages the risk that adversaries will weaponize AI against it. Critically, there is no exemption from accountability requirements for AI systems used in security operations.
MAP: Operationalizing the In / For AI Distinction
MAP requires organizations to document intended use, foreseeable misuse, affected stakeholders, and system boundaries for every AI system — explicitly forcing the question: is this AI system a target (In AI), a tool (For AI), or both? MIT’s empirical finding that 62% of risks materialize post-deployment directly motivates MAP as a continuous, lifecycle-spanning activity rather than a one-time pre-deployment exercise (Slattery et al., 2024, Table C, arXiv:2408.12622). The risk maturity tiers also inform MAP directly: Tier 1 risks require immediate threat modeling and active control verification, Tier 2 risks require architectural preparedness and monitoring, and Tier 3 risks require governance provisions and forward-looking design choices.
MEASURE: Quantifying Security Across the In / For AI Divide
NIST’s seven trustworthiness characteristics — Valid and Reliable, Safe, Secure and Resilient, Accountable and Transparent, Explainable and Interpretable, Privacy-Enhanced, and Fair with Harmful Bias Managed — function as a security control framework when applied through the In / For AI lens. Secure and Resilient is the most direct cybersecurity characteristic, requiring AI systems to maintain confidentiality, integrity, and availability against adversarial attacks. Organizations may consider leveraging available standards such as the NIST Cybersecurity Framework, the NIST Privacy Framework, and the Secure Software Development Framework — explicitly bridging AI security into existing enterprise security programs.
Explainable and Interpretable is a cybersecurity control in NIST’s framework. An AI system that cannot be explained cannot be audited — and an AI system that cannot be audited cannot support effective incident response. For For AI defensive deployments specifically, MEASURE requires ongoing evaluation of whether AI security tools are performing as intended. This is why MEASURE is continuous, not one-time, and why risk maturity tier must be reassessed regularly, as Tier 2 and Tier 3 risks can graduate to higher urgency as adversarial techniques mature.
MANAGE: Responding to the Recursive Risk
The MANAGE function is where the recursive insight — that defensive AI is itself an In AI target — becomes an operational reality. MANAGE requires organizations to prioritize risks, define treatments, plan incident response and recovery, handle residual risk, and drive continuous improvement — applying symmetrically to In AI failures and to For AI defensive tool failures. OWASP’s GenAI Incident Response Guide provides the practitioner-level playbook. MITRE ATLAS’s AI Incident Sharing initiative — a neighborhood watch for AI that allows companies to share anonymized data about real-world attacks — provides the threat intelligence feed. As Tier 2 risks graduate to Tier 1, MANAGE must be ready to accelerate the implementation of the corresponding controls. NIST is explicit: attempting to eliminate negative risk entirely can be counterproductive — a risk management culture helps organizations recognize that not all AI risks are the same, and resources can be allocated purposefully.
NIST as the Governance Bridge
What NIST ultimately provides — and what none of the other four frameworks fully deliver — is the governance bridge between the two halves of the article’s central distinction. The GOVERN–MAP–MEASURE–MANAGE cycle provides the repeatable, accountable, continuously improving process through which IBM’s risk taxonomy, OWASP’s LLM Top 10, MITRE ATLAS’s tactic library, MIT’s 1,700+ risk database, and the maturity tiers all become actionable inputs to organizational security governance — rather than reference documents that sit unread on a shelf.
A Unified Alignment: Both Dimensions Across All Five Frameworks
Maturity Tiers: Tier 1 = Established, actively exploited | Tier 2 = Emerging, demonstrated in research or early-stage operations | Tier 3 = Horizon, theoretically well-founded, limited real-world evidence at scale
| Risk / Capability | Dimension | Maturity | IBM AI Risk Atlas | OWASP LLM Top 10 | MITRE ATLAS Tactic | MIT Domain | NIST AI RMF |
|---|---|---|---|---|---|---|---|
| Data poisoning & backdoors | In AI | Tier 1 | Data Poisoning | LLM04 | ML Attack Staging | 2.2 Security Vulns | MEASURE: Secure & Resilient |
| Supply chain compromise | In AI | Tier 1 | Uncertain Data Provenance | LLM03 | Initial Access | 2.2 + 6 | GOVERN: Supply Chain Policy |
| Prompt injection | In AI | Tier 1 | Prompt Injection family | LLM01 | Execution, Def. Evasion | 4.3 Malicious Actors | MAP: Misuse Scenarios |
| Sensitive data exposure | In AI | Tier 1 | Exposing Personal Info | LLM02 | Exfiltration, Collection | 2.1 Privacy Compromise | MEASURE: Privacy-Enhanced |
| System prompt theft | In AI | Tier 1 | Prompt Leaking | LLM07 | Reconnaissance | 2.2 | MAP: Threat Modeling |
| Hallucination & misinformation | In AI | Tier 1 | Hallucination | LLM09 | Impact | 3.1 False Information | MEASURE: Valid & Reliable |
| AI-powered phishing & deepfakes | For AI (offense) | Tier 1 | Spreading Disinformation | Dangerous Use | Resource Development | 4.2 Fraud & Manipulation | GOVERN: Use Policy |
| AI-lowered barrier to entry | For AI (offense) | Tier 1 | Dangerous Use | Dangerous Use | Resource Development | 4.3 Cyberattacks | GOVERN: Use Policy |
| AI threat detection & SOC | For AI (defense) | Tier 1 | — | COMPASS, IR Guide | AI Incident Sharing | 2.2 Mitigations | MANAGE: Continuous Monitoring |
| AI red teaming | For AI (defense) | Tier 1 | Risk Testing | Red Team Initiative | ATLAS tactic matrix | All domains | MEASURE: Adversarial Testing |
| Governance failure | Both | Tier 1 | Incomplete Evaluation | Governance Checklist | Systemic | 6.5 Governance Failure | GOVERN: Accountability |
| Extraction & inference attacks | In AI | Tier 2 | Extraction Attack | LLM08 | Collection, Exfiltration | 2.1 Privacy Compromise | MEASURE: Privacy-Enhanced |
| Agentic over-privilege | In AI | Tier 2 | Exploit Trust Mismatch | LLM06 | Privilege Escalation, C2 | 5.2 Loss of Agency | GOVERN: Least Privilege |
| RAG-based prompt propagation | In AI | Tier 2 | Prompt Injection family | LLM01 | Execution, Def. Evasion | 4.3 Malicious Actors | MAP: Misuse Scenarios |
| AI-enhanced malware | For AI (offense) | Tier 2 | Harmful Code Generation | LLM05 | Resource Development | 4.3 Cyberattacks | MANAGE: Incident Response |
| AI-assisted vuln. discovery | For AI (off. & def.) | Tier 2 | Extraction Attack | LLM08 | Reconnaissance | 4.3 | MAP: Threat Environment |
| Unexplainable AI actions | In AI | Tier 2 | Unexplainable Output | Governance Checklist | Defense Evasion | 7.4 Transparency | MEASURE: Explainable & Interp. |
| State-sponsored AI operations | For AI (offense) | Tier 1 / 2 | Spreading Disinformation | Dangerous Use | Impact, C2 | 3.2 Info Ecosystem | GOVERN: Scope & Impact |
| Defensive AI as In AI target | In + For AI | Tier 1 / 2 | All agentic risks | LLM06 | All tactics | 7.6 Multi-Agent | MANAGE: Recursive Risk |
| Multi-agent cascading failures | In AI | Tier 3 | Misaligned Actions | LLM06 | C2, Lateral Movement | 7.6 Multi-Agent Risks | MANAGE: Residual Risk |
| AI pursuing misaligned goals | In AI | Tier 3 | Misaligned Actions | — | Impact | 7.1 AI Goals vs Human Val. | MANAGE: Residual Risk |
Conclusion: Five Frameworks, One Integrated Mandate
The distinction between cybersecurity In AI and cybersecurity For AI is not a rhetorical device. It is an organizational design principle — one that determines how security budgets are allocated, how teams are structured, how risk is measured, and how governance is built.
Cybersecurity In AI demands that every AI system be treated as a security asset requiring formal threat modeling, adversarial testing, supply chain scrutiny, runtime monitoring, and incident response planning. IBM’s Risk Atlas provides the risk vocabulary. OWASP’s LLM Top 10 provides the exploitable vulnerability categories. MITRE ATLAS provides the adversary’s playbook. MIT’s Repository provides the evidence base and meta-synthesis.
Cybersecurity For AI demands that organizations recognize AI as a transformative force on the threat landscape itself — one already being weaponized by adversaries at scale. Adversaries are deploying novel AI-enabled malware in active operations, involving tools that dynamically alter behavior mid-execution (Google GTIG, November 2025). CIOs must fight fire with fire and use AI defensively — deploying behavioral detection, anomaly detection, and autonomous response capabilities to counter threats that move faster than human analysts can track. Yet the evidence also counsels precision: the honest picture on AI-assisted vulnerability discovery and state-sponsored AI operations alike reminds us that human direction, governance, and oversight remain central.
NIST AI RMF provides the governance operating system that makes both possible — the GOVERN–MAP–MEASURE–MANAGE cycle that translates risk knowledge into sustained, accountable organizational action, applied simultaneously and coherently across both dimensions.
The recursive insight is the article’s most urgent message: organizations that deploy AI-powered security tools without securing those tools against the attacks documented across the other four frameworks have simply added a new attack surface to their environment. NIST’s MANAGE function is the organizational home for addressing this recursive risk.
Five Imperatives for Security Leaders
- Define which question you are answering before you invest. In AI security investment means threat modeling AI pipelines, red teaming models, securing agentic architectures, and building AI-specific incident response. For AI security investment means deploying AI-powered defensive tools and countering AI-powered offensive threats. Both are necessary. Neither is sufficient without the other.
- Prioritize by maturity tier, not by novelty. Tier 1 risks demand active controls and incident response readiness today. Tier 2 risks demand architectural preparedness and investment in monitoring now. Tier 3 risks demand governance provisions and forward-looking design choices. Organizations that allocate resources according to headline novelty rather than evidence-based maturity will systematically under-invest in the threats that are actually hurting them.
- Govern both dimensions under a unified framework. NIST’s GOVERN–MAP–MEASURE–MANAGE cycle is that framework — providing one organizational process for two distinct but interdependent security challenges, with maturity tier as an explicit input to prioritization.
- Treat the recursive risk as a first-class design problem. Every AI system deployed for defense must be secured against the attacks cataloged for AI systems in general. This is not an edge case — it is the defining challenge of AI security in 2025 and beyond.
- Make governance continuous, not periodic. MIT’s finding that 62% of AI risks materialize post-deployment is a governance mandate: the majority of risk management work happens after launch, not before (Slattery et al., 2024, Table C, arXiv:2408.12622). The maturity tier of any given risk is not fixed — Tier 2 risks regularly graduate to Tier 1 as adversarial techniques become more industrialized. Organizations that treat AI security as a pre-deployment checklist will systematically miss the majority of their actual exposure.
The attack surface is live. The arms race is real. The frameworks to navigate it — IBM, OWASP, MITRE ATLAS, MIT, and NIST — are mature, complementary, and ready to be used together.
Primary Sources
NIST AI Risk Management Framework (AI RMF 1.0): https://nvlpubs.nist.gov/nistpubs/ai/nist.ai.100-1.pdf
MIT AI Risk Repository: https://airisk.mit.edu/
MIT AI Risk Repository — Academic Citation (Slattery et al., 2024, arXiv:2408.12622): https://doi.org/10.48550/arXiv.2408.12622
IBM watsonx AI Risk Atlas: https://www.ibm.com/docs/en/watsonx/saas?topic=ai-risk-atlas
OWASP GenAI Security Project: https://genai.owasp.org/resources/
OWASP LLM Top 10 for 2025: https://genai.owasp.org/llm-top-10/
MITRE ATLAS: https://atlas.mitre.org/
CrowdStrike 2026 Global Threat Report (February 2026): https://www.crowdstrike.com/en-us/blog/crowdstrike-2026-global-threat-report-findings/
Cybersecurity Insiders — Pulse of the AI SOC Report 2025: https://www.cybersecurity-insiders.com/pulse-of-the-ai-soc-report-2025-…
Darktrace — State of AI Cybersecurity Report 2025 (March 2025): https://www.darktrace.com/news/…
Morris II — Nassi et al. (2024), arXiv:2403.02817: https://arxiv.org/abs/2403.02817
Google Project Zero and DeepMind — Big Sleep Agent (2024): https://googleprojectzero.blogspot.com/
Google GTIG — Advances in Threat Actor Usage of AI Tools (November 2025): https://cloud.google.com/blog/topics/threat-intelligence/threat-actor-usage-of-ai-tools
European Parliament Research Service — Storm-1516 AI Disinformation (2025): https://www.europarl.europa.eu/RegData/etudes/BRIE/2025/779259/EPRS_BRI(2025)779259_EN.pdf
Trend Micro ÆSIR Platform (2026): https://www.trendmicro.com/en_us/research/26/a/aesir.html
Qualys — Zero-Day Zero (November 2025): https://blog.qualys.com/vulnerabilities-threat-research/2025/11/24/zero-day-zero-…
Anthropic Threat Intelligence Report (August 2025): https://www.anthropic.com/news/detecting-countering-misuse-aug-2025